Contribution Guide
Source Code Compilation
The Nature compiler is written entirely in C, adhering to the C11 standard. It requires GCC version 11 or higher. The Linux runtime is statically compiled against musl libc. CMake is used as the build tool, requiring version 3.22 or higher.
Build Environment Used for Current Releases:
Apple clang version 16.0.0 (clang-1600.0.26.6)
gcc version 14.2.0 (Ubuntu 14.2.0-4ubuntu2)
Compile the Runtime
# darwin/amd64 architecture: Build only supported on Darwin devices.
rm -rf build-runtime && cmake -B build-runtime -S runtime -DCMAKE_BUILD_TYPE=Release -DCMAKE_TOOLCHAIN_FILE=$(pwd)/cmake/darwin-amd64-toolchain.cmake && cmake --build build-runtime --target runtime
# darwin/arm64 architecture: Build only supported on Darwin devices.
rm -rf build-runtime && cmake -B build-runtime -S runtime -DCMAKE_BUILD_TYPE=Release -DCMAKE_TOOLCHAIN_FILE=$(pwd)/cmake/darwin-arm64-toolchain.cmake && cmake --build build-runtime --target runtime
# linux/amd64 architecture: Requires the x86_64-linux-musl-gcc compiler installed on the build machine.
rm -rf build-runtime && cmake -B build-runtime -S runtime -DCMAKE_BUILD_TYPE=Release -DCMAKE_TOOLCHAIN_FILE=$(pwd)/cmake/linux-amd64-toolchain.cmake && cmake --build build-runtime --target runtime
# linux/arm64 architecture: Requires the aarch64-linux-musl-gcc compiler installed on the build machine.
rm -rf build-runtime && cmake -B build-runtime -S runtime -DCMAKE_BUILD_TYPE=Release -DCMAKE_TOOLCHAIN_FILE=$(pwd)/cmake/linux-arm64-toolchain.cmake && cmake --build build-runtime --target runtime
# linux/riscv64 architecture: Requires the riscv64-linux-musl-gcc compiler installed on the build machine.
rm -rf build-runtime && cmake -B build-runtime -S runtime -DCMAKE_BUILD_TYPE=Release -DCMAKE_TOOLCHAIN_FILE=$(pwd)/cmake/linux-riscv64-toolchain.cmake && cmake --build build-runtime --target runtimeCompiling the runtime generates libruntime.a, which is automatically placed in the corresponding architecture-specific subdirectory under lib, for example: nature/lib/linux_arm64/libruntime.a.
Compile the Source Code
The source code compilation depends on libruntime.a, which is compiled manually as needed.
# Use 'build-release' as the build directory. If cross-compilers are installed, specify the target architecture using TOOLCHAIN_FILE.
# cmake -B build-release -DCMAKE_VERBOSE_MAKEFILE=ON -DCMAKE_TOOLCHAIN_FILE=$(pwd)/cmake/linux-amd64-toolchain.cmake -DCMAKE_BUILD_TYPE=Release -DCPACK_OUTPUT_FILE_PREFIX=$(pwd)/release
cmake -B build-release -DCMAKE_VERBOSE_MAKEFILE=ON -DCMAKE_BUILD_TYPE=Release -DCPACK_OUTPUT_FILE_PREFIX=$(pwd)/release
# Compile
cmake --build build-release
# Test
cmake --build build-release --target test
# Install (Defaults to /usr/local/nature, may require sudo privileges)
cmake --build build-release --target install
# Package (Creates an archive in the 'release' directory)
cmake --build build-release --target packageCoding Standards
File Naming
- Source files: Use lowercase letters and end with
.c. - Header files: Use lowercase letters and end with
.h. - Filenames should be concise and clearly indicate the module's purpose.
Function Naming
- Use
snake_case(lowercase letters and underscores). - Prefix functions with the module name to avoid naming collisions.
- Functions not intended for external use (internal linkage) should be declared with the
statickeyword within the.cfile.
Type Naming
- Suffix structure type names with
_t. - Define types using
typedef.
typedef struct module_t { ... } module_t;
typedef struct coroutine_t { ... } coroutine_t;Variable Naming
- Use
snake_case. - Variable names should clearly convey their purpose.
- Short names are acceptable for temporary variables with limited scope.
Code Formatting
Code should be formatted according to the .clang-format file located in the project's root directory.
Commenting Guidelines
Comments are optional for simple modules/functions but required for complex ones. Comments should be clear and explanatory. English is preferred for all comments. Existing Chinese comments in the codebase will eventually be translated to English.
Testing Guidelines
All test files reside in the tests directory. Source code tests are located in tests/features. Testing is implemented using CMake's CTest framework.
tests/features utilizes three types of source code testing methods. Refer to the existing examples within the tests directory:
- Directory-based tests
- Single file tests
testararchive tests
Git Branch Management
All Nature-related repositories follow the Github Flow workflow.
This means the master branch always contains the latest, thoroughly tested code. Feature development and bug fixes should be done on separate branches checked out from master. Once development is complete, submit a Pull Request (PR) to merge into master. After merging, the feature/bugfix branch should be deleted.
How to Contribute Code?
The Nature programming language uses GitHub as its primary code repository. Currently, there are no committees or similar organizations. Development decisions, PR merges, reviews, and releases are handled by the project initiator, weiwenhao.
For code contributions involving Features, Refactoring, Standard Library additions, or complex Bug Fixes, you must first propose your idea and discuss it in a GitHub Issue or via email. Development should only begin after the discussion concludes with approval. Once development is complete, submit a Pull Request (PR). Simple Bug Fixes can be submitted directly as PRs without prior discussion.
After developing Features, Standard Library additions, or Bug Fixes, test cases must be added. Once the functionality passes its specific tests, you must run the full CMake CTest regression suite locally before submitting the PR.
DeepWiki
https://deepwiki.com/nature-lang/nature Refer to deepwiki and subsequent chapters to understand the source structure and flow of nature.
Directory Structure
├── CMakeLists.txt # Main project build configuration file
├── LICENSE-APACHE # Apache License
├── LICENSE-MIT # MIT License
├── README.md # English documentation
├── README_CN.md # Chinese documentation
├── VERSION # Version information file
├── cmake # CMake toolchains and build configuration directory
├── cmd # Command-line tool related code
├── config # Compiler configuration file directory
├── include # Third-party library header file directory
│ ├── mach # MacOS system call related header files
│ ├── mach-o # MacOS executable format related header files
│ ├── uv # libuv asynchronous IO library header files
│ ├── uv.h
│ └── yaml.h # yaml parsing library header file
├── lib # Build outputs and dependency library directory
│ ├── darwin_amd64 # MacOS x86_64 architecture library files
│ ├── darwin_arm64 # MacOS ARM architecture library files
│ ├── linux_amd64 # Linux x86_64 architecture library files
│ └── linux_arm64 # Linux ARM architecture library files
├── main.c # Program entry point file
├── nls # Internationalization resource file directory
├── package # Packaging related configurations and scripts
├── runtime
│ ├── CMakeLists.txt # Runtime library build configuration
│ ├── nutils # Helper functions depended on by user code (e.g., vec/map/set)
│ ├── runtime.h # Runtime entry point
├── src
│ ├── binary # Assembler and linker source code
│ ├── build # Compiler build entry point
│ ├── lower # IR lowering and optimization related code
│ ├── native # Target platform code generation
│ ├── register # Register allocation related code
│ ├── semantic # Semantic analysis related code
│ ├── symbol # Symbol table related code
│ ├── syntax # Syntax analysis related code
│ ├── ast.h # Abstract Syntax Tree definition
│ ├── cfg.h # Control Flow Graph definition
│ ├── debug # Debug information related code
│ ├── error.h # Error handling definitions
│ ├── linear.h # AST to LIR compilation logic
│ ├── lir.h # Low-level IR definition
│ ├── module.h # Nature compiles module by module; module-related type definitions
│ ├── package.h # Package management definitions
│ ├── ssa.h # SSA form definitions
│ └── types.h # Basic type definitions
├── std # Standard library source code
├── tests # Test related files
│ ├── CMakeLists.txt # Test build configuration
│ ├── features # Feature test cases
│ ├── test.h # Test framework header file
│ ├── test_arm64_encoding.c # ARM64 encoding test
│ ├── test_bitmap.c # Bitmap test
│ ├── test_hello.c # Hello World example test
└── utils # Common utility library
├── autobuf.h # Auto-expanding buffer
├── bitmap.h # Bitmap operations
├── ct_list.h # Dynamic array
├── custom_links.h # Custom linked data, depended on by runtime/compiler
├── error.h # Error handling
├── exec.h # Test process execution
├── helper.h # Common helper functions
├── linked.h # Linked list operations
├── log.h # Compiler logging
├── mutex.h # Mutex lock
├── sc_map.h # Hash map implementation
├── slice.h # Dynamic pointer array
├── stack.h # Stack data structure
├── string_view.h # String view
├── table.h # Hash table (deprecated, use sc_map instead)
├── toml.h # TOML configuration parsing
├── type.h # Nature type definitions and reflection implementation shared by runtime/compiler
└── ymal # YAML parsing relatedCompilation Flow
Nature's LSP (Language Server Protocol) is implemented in Rust and shares the same frontend logic as the Nature compiler. If you are more familiar with Rust, you can refer directly to the Nature LSP source code.
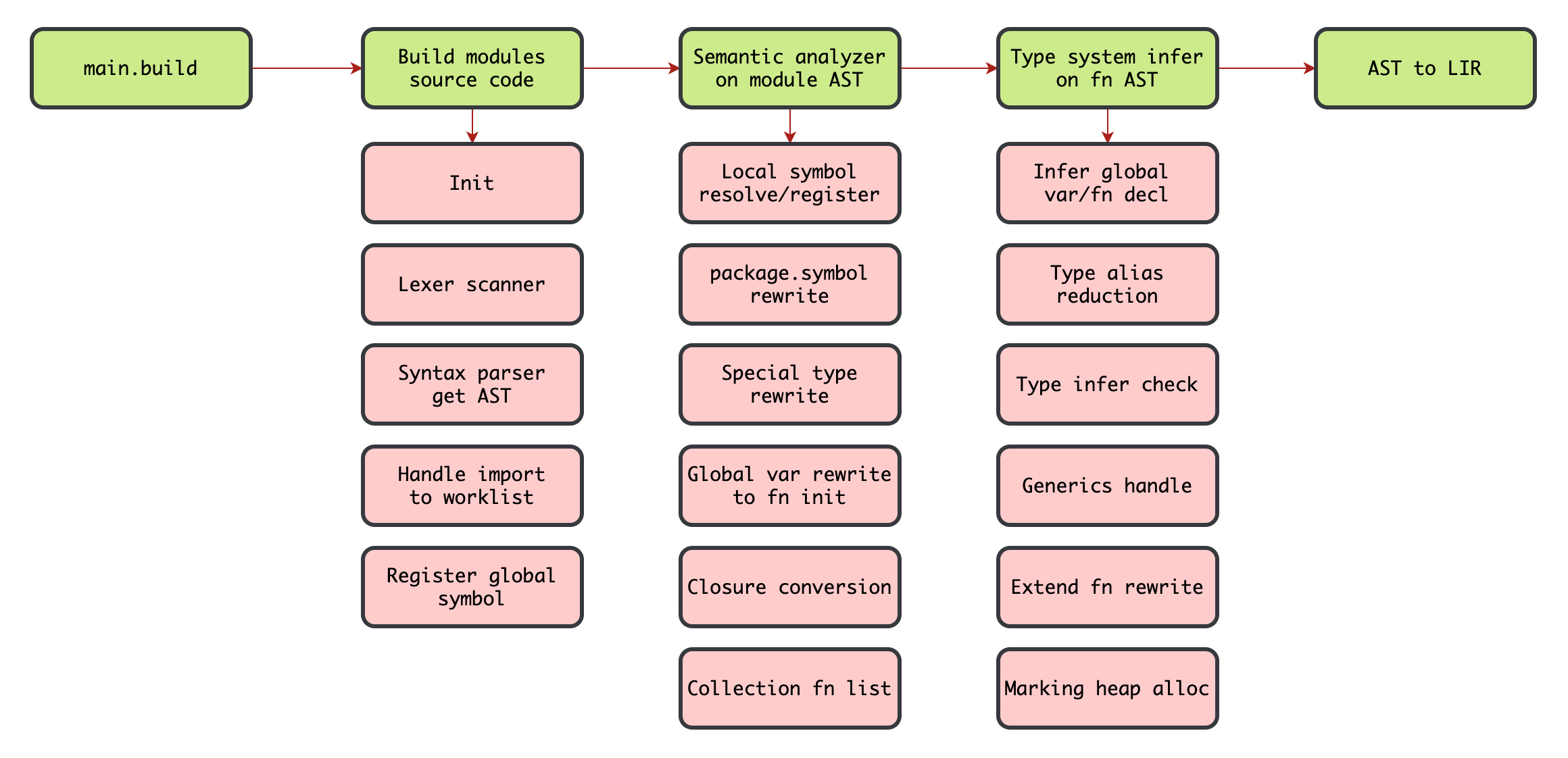
Compiler Frontend
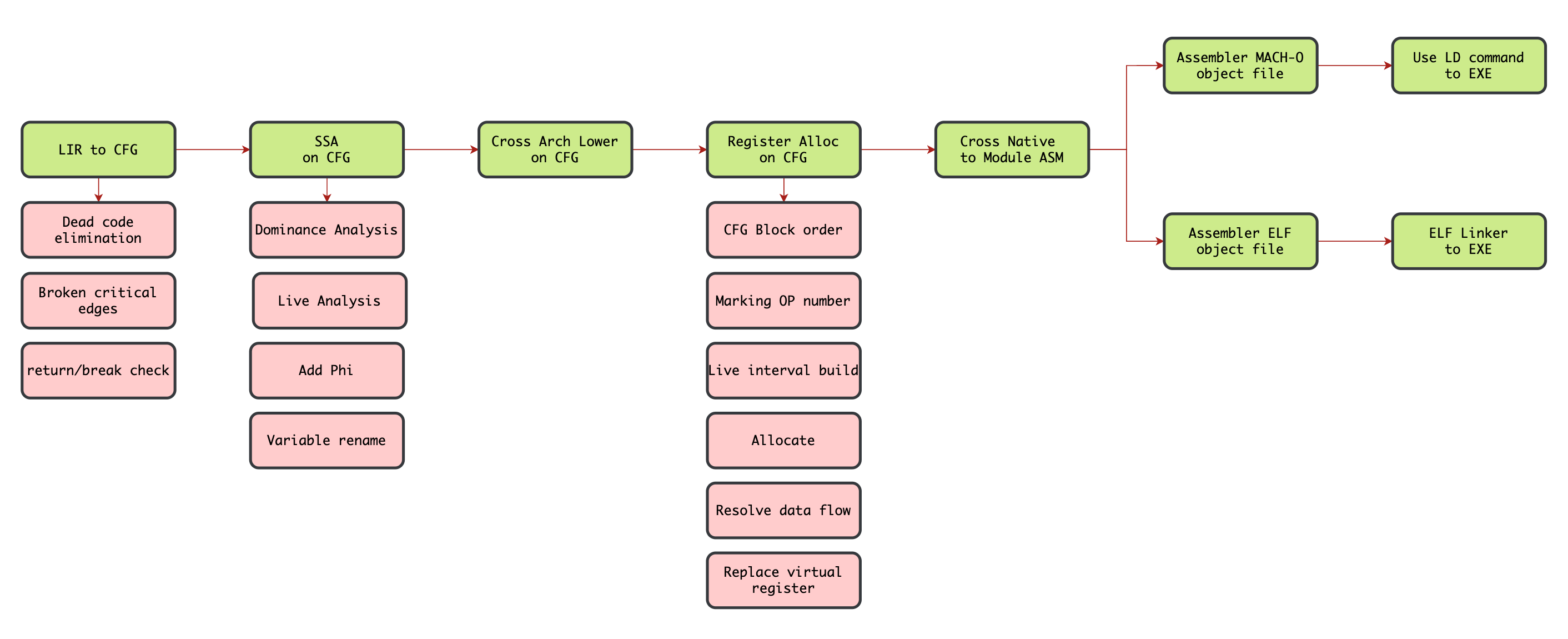
Compiler Backend
Related Code Locations
main.build->src/build/build.c#build(Entry Point)- Build modules ->
src/build/build.c#build_modules - Semantic analyzer ->
src/semantic/analyzer.c#analyzer - Type system infer ->
src/semantic/infer.c#pre_inferandinfer - AST to LIR ->
src/linear.c#linear - LIR to CFG ->
src/cfg.c#cfg - SSA on CFG ->
src/ssa.c#ssa - Cross Arch Lower ->
src/lower - Register Alloc ->
src/register/linearscan.c#reg_alloc - Cross Native ->
src/native - Assembler file ->
src/build/build.c#build_assembler - Elf Linker ->
src/build/build.c#build_elf_exe->src/binary/elf/linker.c#elf_exe_file_format - Mach-O LD ->
src/build/build.c#build_mach_exe
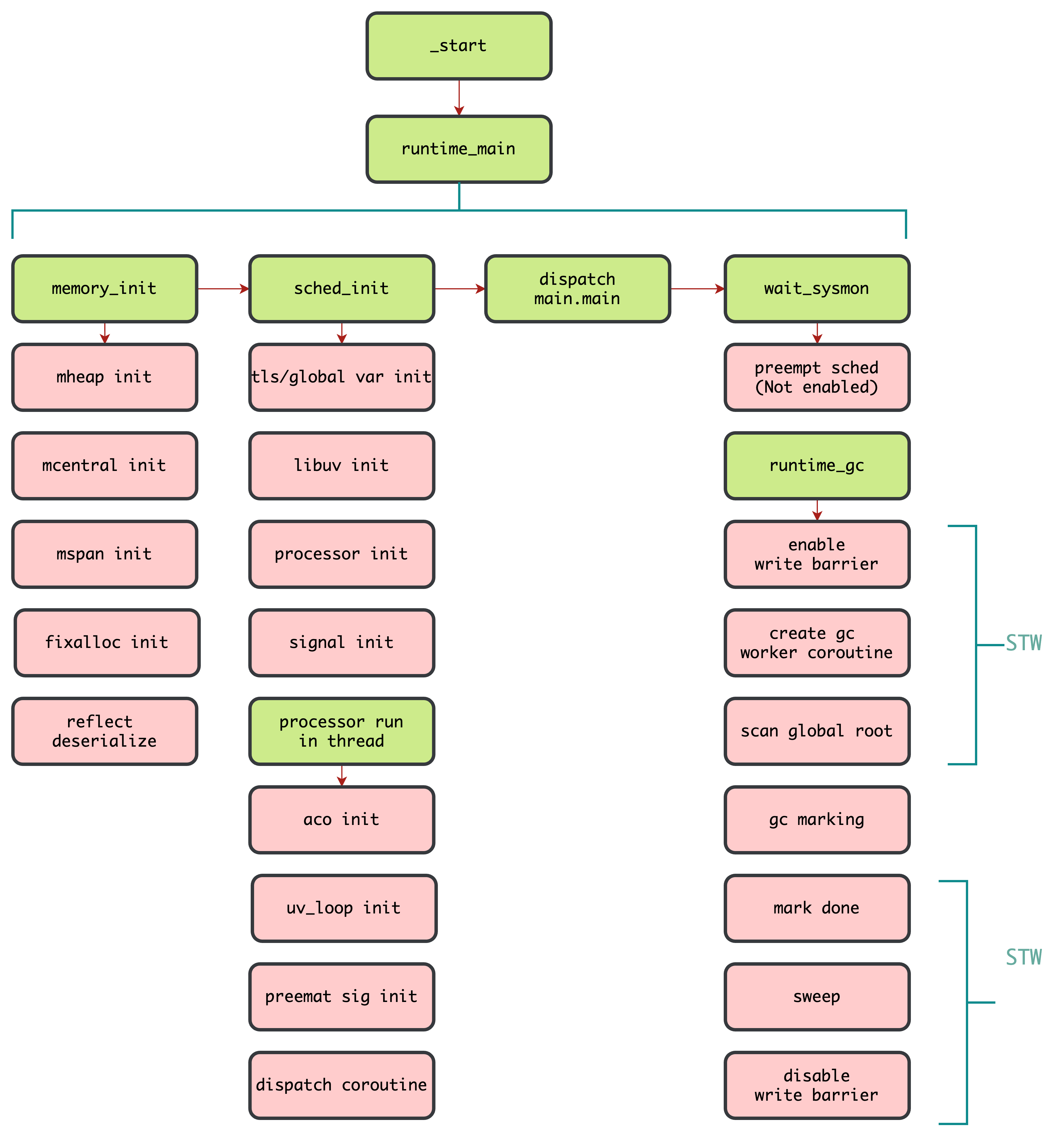
Runtime Flow
Related Code Locations
runtime_main->runtime/runtime.c#runtime_mainsched_init->runtime/processor.c#sched_initprocessor_run->runtime/processor.c#processor_runwait_sysmon->runtime/sysmon.c#wait_sysmonruntime_gc->runtime/collector.c#runtime_gc
Lexer Scanner
src/syntax/scanner.c
This is the lexical analyzer (Scanner), primarily responsible for converting source code text into a sequence of tokens. The Lexer Scanner is the first stage of the compiler frontend, providing the foundation for subsequent syntax analysis.
Syntax Parser
src/syntax/parser.c
This file implements the Syntax Parser, which is mainly responsible for converting the token sequence generated by the Lexer Scanner into an Abstract Syntax Tree (AST). The parser uses a Recursive Descent approach and is a core component of the compiler frontend.
Expression parsing employs the Operator Precedence Climbing algorithm, implemented via parser_expr() and parser_precedence_expr(). parser_expr handles several special expressions, such as go, match, fndef, and struct_new.
Error checking and reporting use the PARSER_ASSERTF macro. Currently, the compiler does not implement error recovery mechanisms. The LSP has implemented relevant error recovery, allowing it to continue parsing beyond errors.
Ambiguous symbols are resolved using lookahead parsing to determine their semantics.
Semantic Analyzer
src/semantic/analyzer.c
This implements the Semantic Analyzer within the compiler, primarily responsible for:
- Symbol resolution and scope analysis.
- Generating unique identifiers for variables and functions.
- Handling closure variable capture.
- Module import and symbol visibility analysis.
- Type alias resolution.
- Global variable initialization.
- Using the
ANALYZER_ASSERTFmacro for error checking and reporting. - Transforming the module-level AST into function-level units, as subsequent stages operate at the function level.
Type System Infer
src/semantic/infer.c
This is the Type Inference module in the compiler, primarily responsible for:
- Type inference and checking:
- Type inference for variable declarations.
- Expression type inference and checking.
- Function call argument type checking.
- Generic type specialization and instantiation.
- Type Reduction:
- Reducing Type Aliases to their concrete types.
- Handling type reduction for composite types (arrays, pointers, structs, etc.).
- Type reduction for generic parameters.
- Main functions:
pre_infer: Pre-processes global variable and function declarations, mainly handling function signatures without processing bodies.infer: Entry function, handles type inference for the entire module.infer_expr: Expression type inference.reduction_type: Type reduction and type parameter handling.infer_fndef: Type inference for function definitions.generics_special_fn: Generic function handling.
It uses the INFER_ASSERTF macro for type error checking and reporting. This module is the core of the compiler's type system, ensuring correct type usage in the program and providing type information support for subsequent code generation. It executes after the semantic analysis phase and before code generation, playing a crucial role in ensuring type safety.
Linear to LIR
src/linear.c
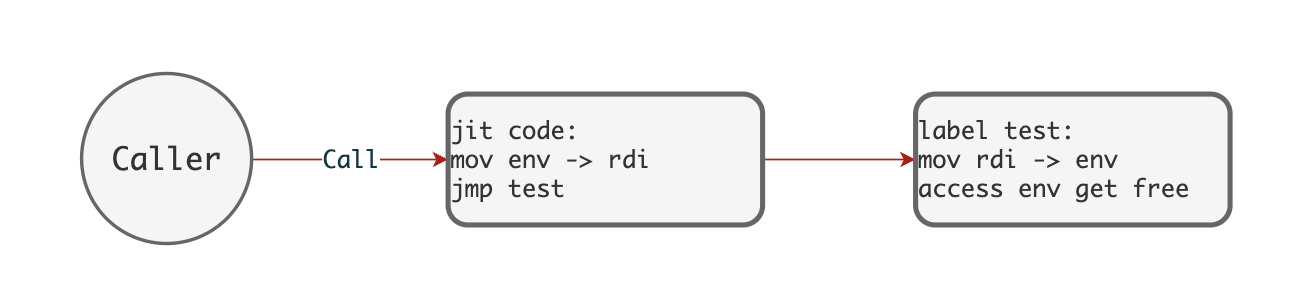
This is the compiler's Linear Intermediate Representation (Linear IR) generation module, responsible for converting the AST into a linear intermediate code representation. It currently includes numerous runtime call invocations. Future versions should use inline optimization to convert runtime calls into LIR implementations.
Closure compilation uses a JIT-based approach, simplifying the compilation process, and the caller does not need to be concerned with the closure's captured environment. See the diagram below:
Nature requires variables to be assigned a value upon initialization. However, it is more lenient with struct initialization, assigning default values to most types:
- The default value for
intis 0. - The default value for
stringis the empty string''. - The default values for
vec/map/setare the corresponding empty containers. tup/structrecursively assign default values to their members.
Certain types must be manually assigned because a reasonable default value cannot be set, such as function types (fn) and pointer types (ptr).
LIR to CFG
src/cfg.c
This module builds the Control Flow Graph (CFG) for the compiler.
- Basic Block Construction:
- Implemented via
cfg_build. - Splits linear IR code into basic blocks based on labels and jump instructions.
- Establishes sequential and jump relationships between basic blocks.
- Implemented via
- Critical Edge Handling:
- Implemented via
broken_critical_edges. - Handles critical edges in the control flow graph.
- Inserts empty intermediate basic blocks to optimize data flow analysis. The subsequent
resolve_data_flowin register allocation does not allow critical edges.
- Implemented via
- Unreachable Code Elimination:
- Implemented via
cfg_pruning. - Removes basic blocks unreachable from the entry block.
- Maintains predecessor and successor relationships between basic blocks.
- Implemented via
- Return Check:
- Return statement check: Ensures all execution paths have a return statement.
- Ret statement check: Ensures correct Ret statements within
match/catchstructures.
SSA
src/ssa.c
This file implements the transformation into SSA (Static Single Assignment) form, an important step in compiler optimization. Main functionalities include:
- Dominance Analysis:
ssa_domers: Computes the dominator set for each basic block.ssa_imm_domer: Computes the immediate dominator for each basic block.ssa_df: Computes dominance frontiers.
- Variable Liveness Analysis:
ssa_use_def: Analyzes variable usage and definitions within each basic block.ssa_live: Performs liveness analysis, computing live-in and live-out variables for each basic block.
- SSA Transformation:
ssa_add_phi: Inserts φ (phi) functions where necessary.ssa_rename: Renames variables to ensure each variable is assigned only once.
The primary characteristic of SSA form is that each variable is assigned only once. This allows for:
- Simplified data flow analysis.
- Facilitation of subsequent code optimizations.
- Clearer definition-use relationships for variables.
Currently, the Nature compiler has not yet begun implementing optimizations based on SSA form.
SSA Example 1:
int foo = 1
foo = foo + 2
if (true) {
int car = 4
foo = 2
} else {
int car = 5
foo = 3
}
println(foo)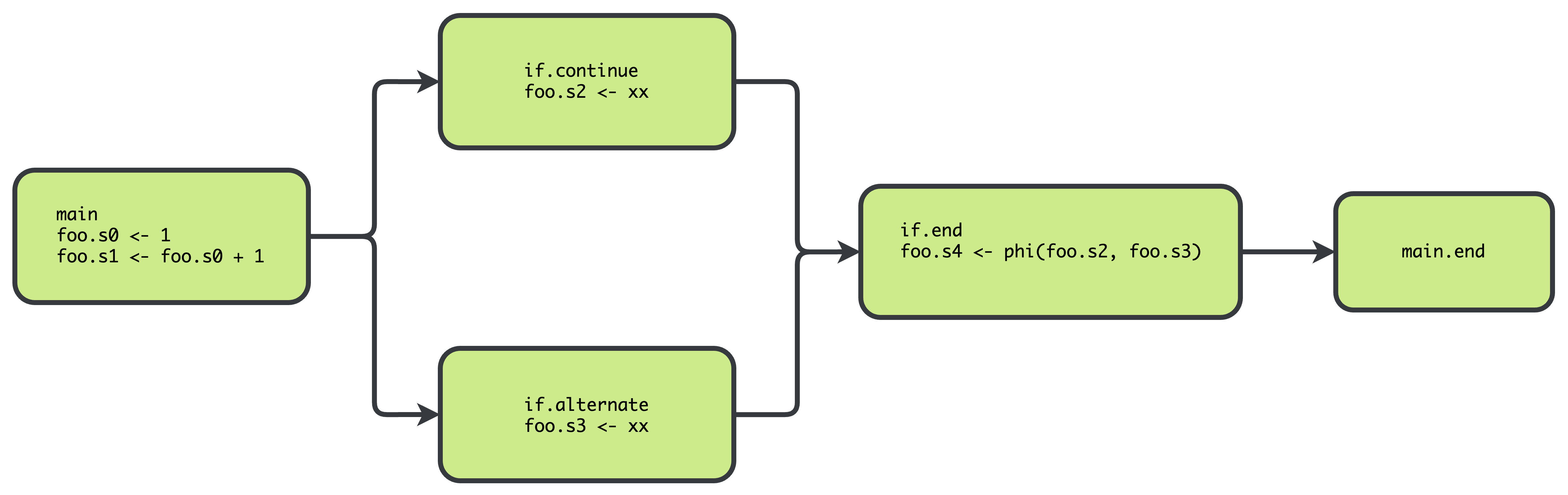
SSA Example 2:
int foo = 0
for (int i = 0; i <= 100; i+=1) {
if ((i % 2) == 0) {
foo += i
}
}
println(foo)
Cross Lower
src/lower
The lower stage is primarily responsible for converting LIR into architecture-specific instruction forms for AMD64/ARM64. For instance, on the AMD64 architecture, ADD is a two-operand instruction where one source operand and the destination operand must be the same register. Another example is idiv, which uses the rdx:rax register pair as the dividend.
It also implements architecture-specific Calling Conventions. Taking the AMD64 architecture as an example:
- When calling a function, arguments are passed in specific registers in order: the first argument uses
rdi, the second usesrsi, and so on. - The function return value is uniformly placed in the
raxregister.
These architecture-related physical register (Fixed Register) constraints must be handled before register allocation. This allows the subsequent register allocation phase to accurately calculate the live range of each variable (including virtual and physical registers), leading to better allocation decisions.
Special Handling for Array Parameter Passing:
In C, when an array is passed as a function parameter, it automatically decays into a pointer, effectively passing the array's base address. In the Nature programming language, however, the intention is for array parameters to be passed by value (i.e., copying the entire array content). To achieve this, during the processing of function call arguments (Lower Call Args):
- Allocate space on the stack equal to the size of the original array.
- Copy the entire content of the original array into this allocated stack space.
- Pass the address of this stack space as the argument to the function.
This ensures that modifications to the array within the function do not affect the original array, achieving true value-passing semantics. If C-like array reference passing is desired, simply using arr as anyptr will bypass this copying behavior and pass the data by reference.
Register Alloc
src/register
Register allocation is the process of mapping program variables to physical registers. Since registers are limited in number but fast to access, effective register allocation significantly impacts program performance.
The Nature compiler employs a linear scan algorithm based on SSA-form LIR for register allocation. It primarily references two papers:
- Linear Scan Register Allocation for the Java HotSpot Client Compiler. — Wimmer, C.
- Linear Scan Register Allocation on SSA Form. — Christian Wimmer, Michael Franz
Main components:
interval.c: Builds live intervals for variables.allocate.c: Implements the core allocation algorithm.register.c: Manages physical registers.amd64.c/arm64.c: Register definitions for different architectures.
Workflow:
interval_block_order: Sort basic blocks.linear_prehandle: Add instruction sequence numbers.interval_build: Build live intervals for virtual variables and physical registers.allocate_walk: Traverse live intervals, allocate physical registers, and handle register spilling (moving variables to memory when registers are full).resolve_data_flow: Handle data flow across basic block boundaries and eliminate PHI operations.replace_virtual_register: Replace virtual registers with allocated physical registers.
After register allocation, the LIR no longer contains virtual variables (VAR), making it easier to convert to assembly code. In the current version, register allocation performance is relatively poor due to frequent register spills caused by numerous runtime calls.
Cross Native
src/native
The native stage converts the LIR, after register allocation is complete, into assembly code. This assembly code conforms to the syntax specifications and instruction sets of the AMD64/ARM64 architectures. In practice, it's actually converted into a C language array representation rather than directly into textual assembly.
Example: list_push(operations, AMD64_ASM("mov", dst_operand, src_operand));
Assembler
src/binary/encoding/amd64/opcode.c — AMD64 assembler
src/binary/encoding/arm64/opcode.c — ARM64 assembler
The main task of the assembler is to convert the assembly syntax arrays generated by the Native stage into the binary machine code required by the corresponding CPU architecture.
For the AMD64 architecture, the amd64_asm_inst_encoding function encodes assembly instructions into machine code. This process generates a trie (prefix tree) to select the appropriate AMD64 instruction. After instruction selection, various parts like prefixes, opcode, ModR/M byte, SIB byte, and potentially displacement and immediate values are filled in, ultimately generating variable-length machine code. Example of the trie constructed from the AMD64 instruction set:
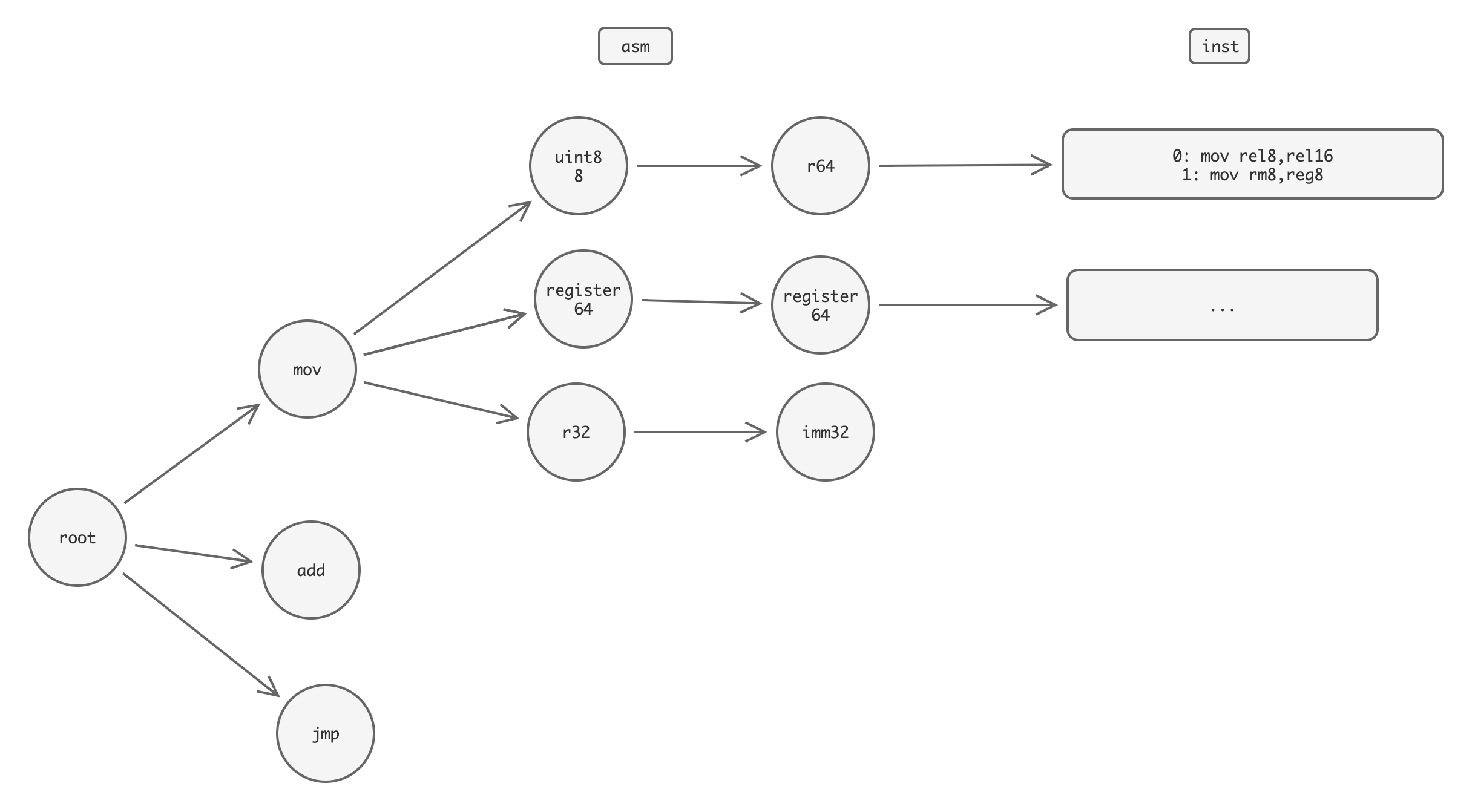
On the ARM64 architecture, the arm64_asm_inst_encoding function uses a simpler implementation. It matches the assembly instruction to the corresponding opcode handler function and then generates fixed 4-byte length machine code.
These assembler functions are called during the generation of operating system-specific object files. The relevant code is located in:
src/build/build.c#elf_assembler_module -> elf_amd64_operation_encodings/elf_arm64_operation_encodings
src/build/build.c#mach_assembler_module -> mach_amd64_operation_encodings/mach_arm64_operation_encodings
The encodings functions are primarily responsible for encoding assembly instructions into machine code and handling symbol relocation issues. They work in two passes:
- The first pass handles the encoding of assembly instructions and relocation of known symbols.
- The second pass handles symbol references that could not be resolved in the first pass.
Finally, all encoded instruction data is written into the code section, and the instruction length of generated function labels (fn label) is recorded, paving the way for the subsequent reflection mechanism.
Linker
src/binary/elf/linker.c#elf_exe_file_format — ELF linker implementation
The linker is responsible for merging multiple object/archive files into a single executable file. Nature's linker is a simple implementation, primarily focusing on static linking. Its workflow involves:
elf_resolve_common_symbols: Handles COMMON symbols, allocating them to the.bsssection.elf_build_got_entries: Builds GOT/PLT entries, handling relocations related to dynamic linking (though dynamic linking itself is not fully supported).set_section_sizes: Calculates the sizes of various sections.alloc_section_names: Allocates the section name string table.layout_sections: Lays out all sections, calculating their virtual addresses and file offsets.elf_relocate_symbols: Relocates symbols, calculating their final addresses.elf_relocate_sections: Processes all relocation sections.elf_fill_got: Fills the Global Offset Table (GOT).elf_output: Generates the final ELF executable file.
It does not support dynamic linking, version control, or debug information processing.
Runtime Sched
runtime/processor.c#sched_init
Nature's scheduler (sched) is a simple implementation resembling Go's GMP scheduling model, built around a Processor + Coroutine model.
Core Components
n_processor_t: Processor struct, representing an execution unit (like Go's P).coroutine_t: Coroutine struct, representing an executable task (like Go's G).- Shared processor list (
share_processor_list) and solo processor list (solo_processor_list).
Main Functions
- Coroutine scheduling: Creating, running, switching, and destroying coroutines.
- Processor management: Creating and managing multiple processor instances.
- Non-preemptive scheduling: Yielding occurs through safepoints.
- GC related: Supports safepoints for Stop-The-World (STW) garbage collection.
Key Functions
sched_init(): Scheduler initialization.processor_run(): Processor main loop.coroutine_resume(): Resume coroutine execution.rt_coroutine_dispatch(): Coroutine scheduling dispatch.
Tips
- Scheduling is cooperative based on safepoints. Safepoints are inserted at function ends and before function calls. Therefore, long-running
forloops without function calls can prevent other coroutines from being scheduled and block GC. - Nature currently has a very basic coroutine scheduler. Once created, coroutines are generally balanced and fixed to a Processor.
- Nature uses shared stack coroutines. This allows for more lightweight coroutine stacks, faster creation, and faster switching. Shared stack diagram:
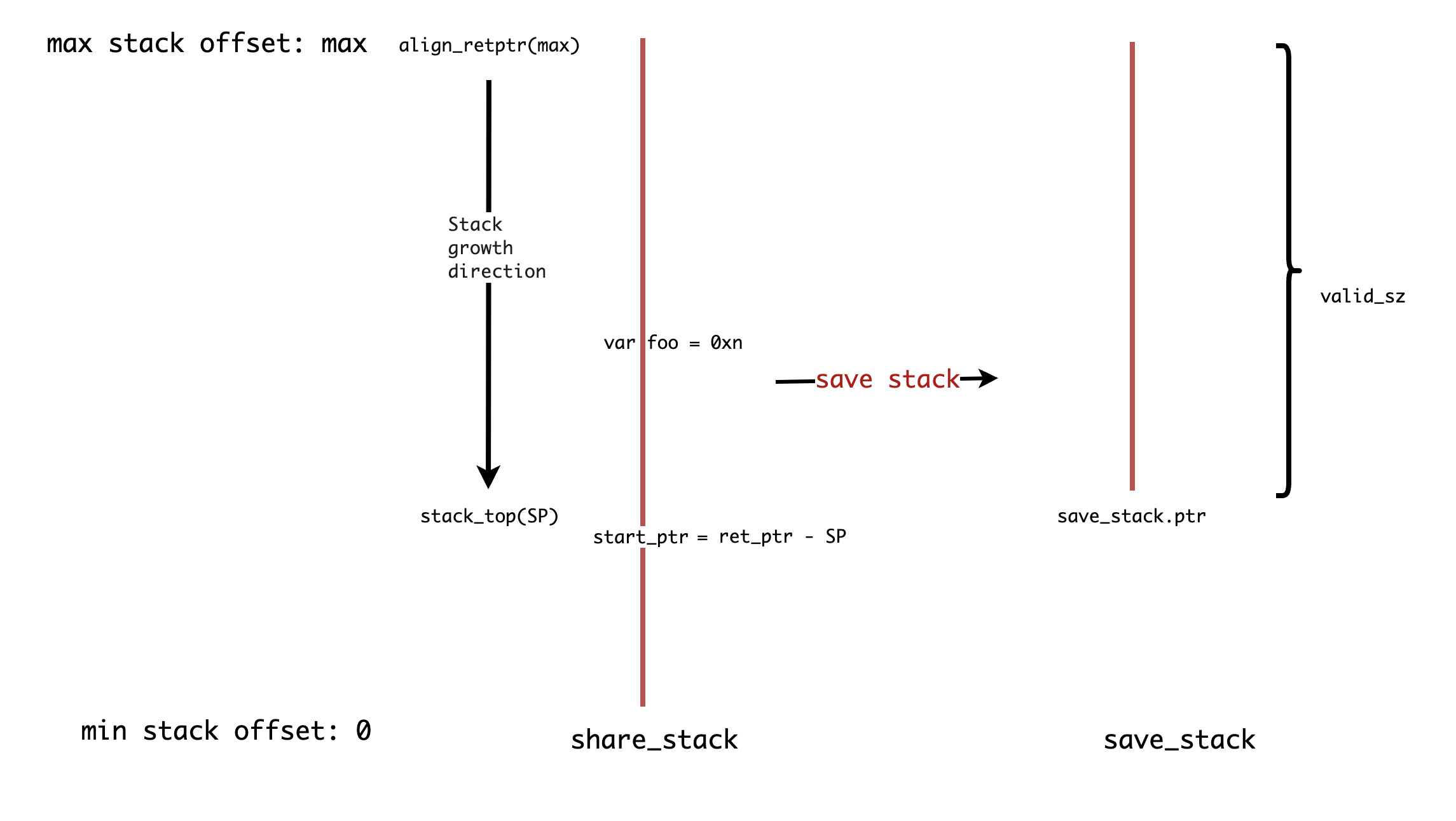
- Before a yield,
valid_szandSPare not fixed, making it impossible to calculate the exact location of thefoovariable on thesave_stack! - If
valid_sz's position were fixed, the offsetalign_retpt - 0xnwould equalsave_stack.ptr + valid_sz - 0xn.
- Before a yield,
- A significant issue with shared stacks is that the stack pointer becomes invalid for other coroutines upon yielding. Therefore, obtaining
&qin Nature results in something likerawptr<T>, an unverified, unsafe pointer. This might be solvable through escape analysis or stack switching, but Nature currently implements neither. If you can guarantee no coroutine yield will occur, you can userawptr. Otherwise, you must explicitly allocate data on the heap.
Runtime GC
runtime/collector.c#runtime_gc
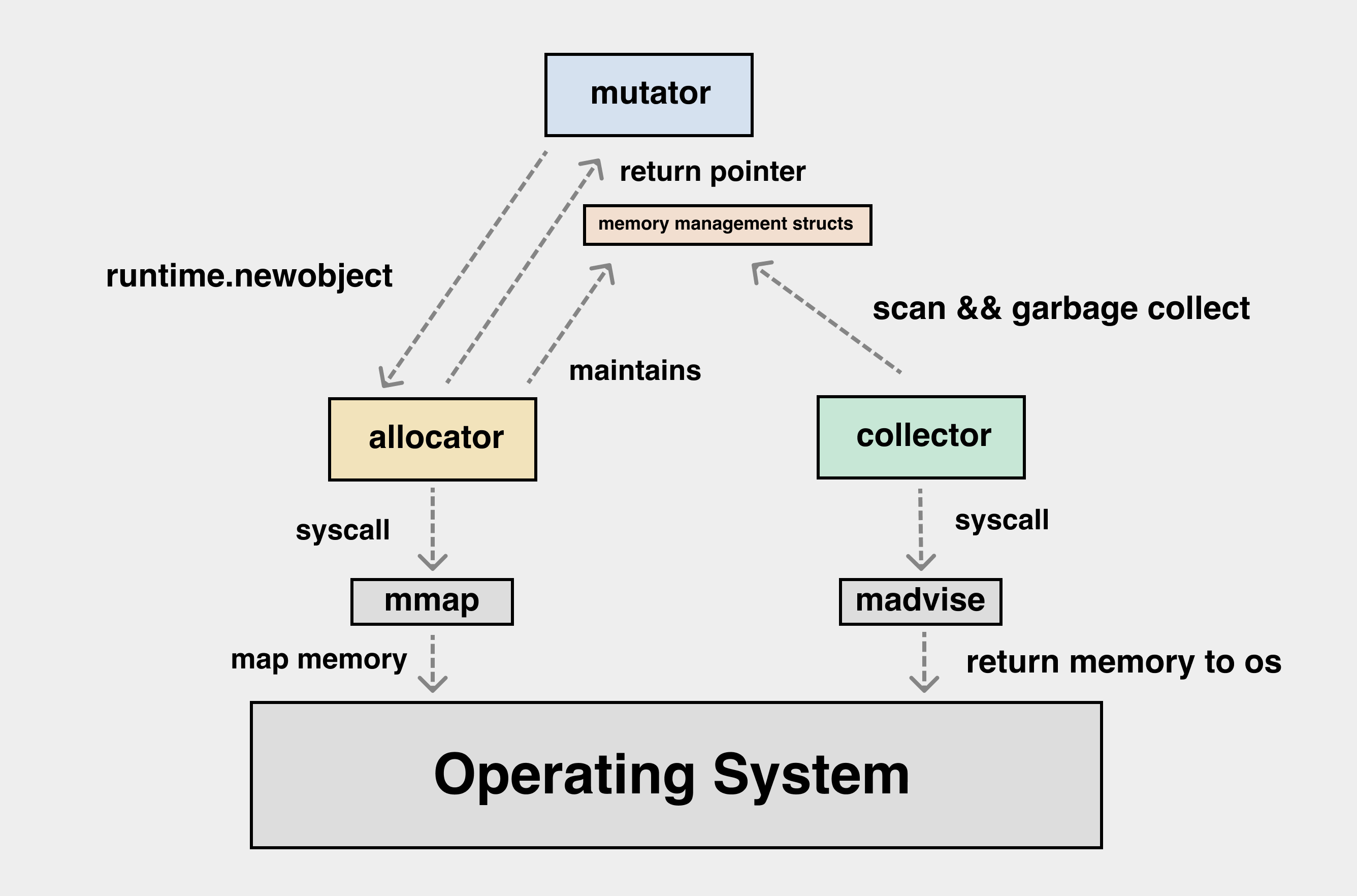
GC (Garbage Collection) is an automatic memory management mechanism that automatically identifies and reclaims memory space no longer in use by the program, thereby preventing memory leaks and simplifying memory management. GC typically consists of three main components:
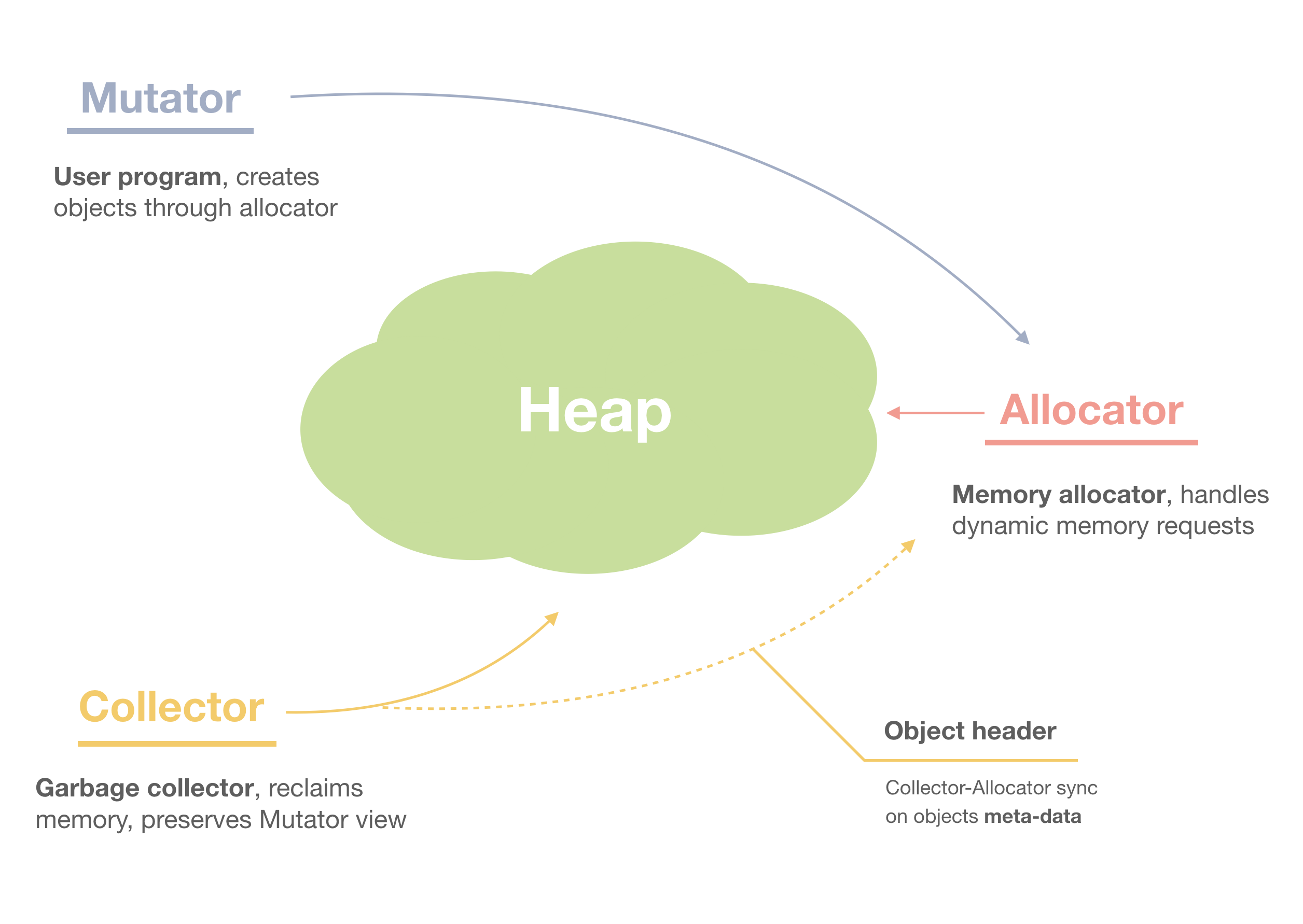
- Mutator: Also known as the user program. During its operation, it performs three types of operations related to heap memory.
var a = malloc() // New: Allocate a new piece of memory (obj) from the heap for local variable a var b = a.foo // Read: Read the foo field of obj a and assign it to local variable b a.foo = null // Write: Clear a.foo b.bar = a.bar // Write: Modify the pointer of b.bar - Allocator: The memory allocator, responsible for requesting free memory from the heap. The allocated memory unit is typically called an object (
obj), which consists of one or more fields. - Collector: The garbage collector, responsible for identifying and cleaning up objects (
obj) that are no longer used by the user program.
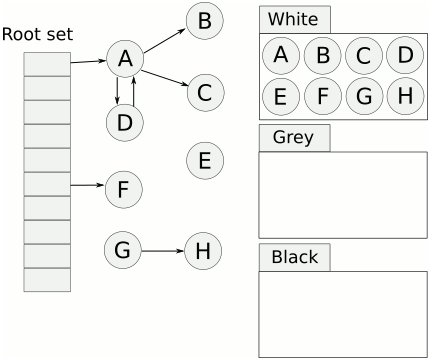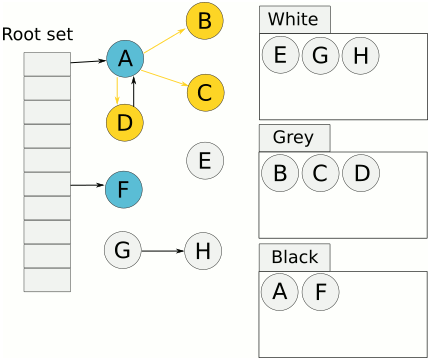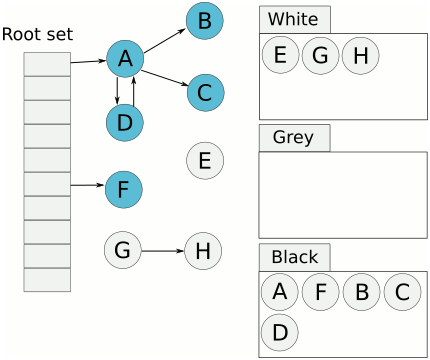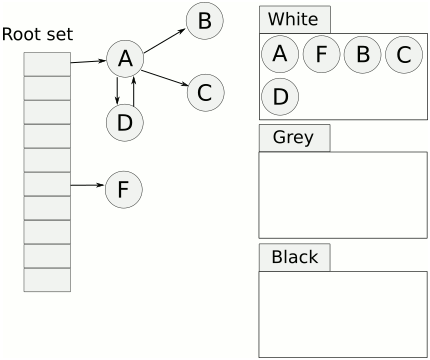
Nature's compiler uses Tri-color Marking GC, as illustrated below:
Incremental and Concurrent GC
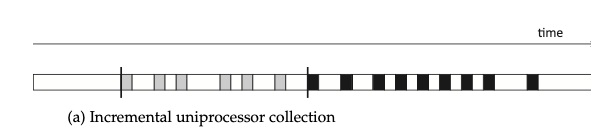
Incremental garbage collection typically refers to a single-threaded model where the collector's work is divided into smaller sub-tasks, allowing the mutator (white blocks) and collector (grey/black blocks) to execute alternately. Incremental GC reduces the duration of Stop-The-World (STW) pauses perceived by the user program.
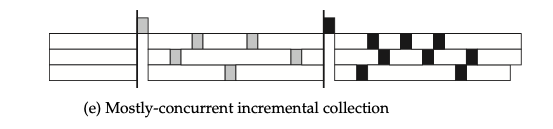
Extending incremental GC techniques to multi-core, multi-threaded environments allows for a form of incremental GC that can run concurrently most of the time. This is the GC approach adopted by both Go and Nature.
Although each thread might block its mutator during GC work, from a multi-threaded perspective, there will always be some user program threads making progress. Therefore, in a multi-threaded context, the definition of STW (Stop-The-World) needs refinement: only when the collector blocks all threads simultaneously is it considered a true STW. For example, the diagram above shows two STW phases.
The primary goal of both incremental and concurrent collectors is to minimize the pause times perceptible to the mutator. Ideally, a concurrent collector could run entirely in parallel with the mutator (i.e., different threads perform their own collection work without interference, although this is challenging in a coroutine scheduling model), potentially shortening the overall execution time.
Concurrent collection inevitably requires some form of communication and synchronization between the mutator and the collector, which manifests as mutator barrier techniques.
Barrier Techniques
As mentioned in the incremental GC section, simply interleaving collector sub-tasks with the mutator is not straightforward. The main problem is that the mutator can interfere with the collector's completed work, leading to GC correctness issues.
GC correctness issues are severe, as they can lead to the erroneous collection of memory still in use.
Barrier techniques intercept the mutator's operations on objects (obj) to ensure GC correctness. We previously discussed three types of mutator operations related to heap memory. Barrier techniques primarily intercept the Read and Write operations.
// var b = a.foo // Read: Read the foo field of obj a and assign it to local variable b
var b = read_barrier(a, foo) // Intercepting Read operations is called a read barrier
// a.foo = null // Write: Clear a.foo
write_barrier(a, foo, null) // Intercepting Write operations is called a write barrier
// b.bar = a.bar // Write: Modify the pointer of b.bar
write_barrier(b, bar, read_barrier(a, bar)) // Combines write and read barriersLisp statistics show that Read operations occur much more frequently than Write operations, making read barriers very expensive. Therefore, mark-sweep garbage collectors typically use write barriers.
Tri-color Marking Garbage Collection
Tri-color marking GC is a type of incremental mark-sweep garbage collection algorithm. It categorizes objects (obj) into three colors during GC:
- White: Objects not yet scanned by the collector.
- Grey: Objects scanned by the collector (added to the worklist), but whose fields have not yet been fully scanned.
- Black: Objects scanned by the collector, and all of whose fields have also been scanned.
The mention of a worklist implies a breadth-first traversal, which is essentially what tri-color marking does. Starting from the mutator roots, it traverses all reachable objects. Objects that are not reached are considered garbage and need to be cleaned up.
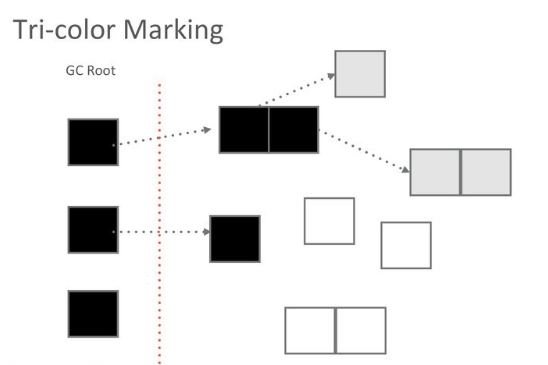
The "incremental" aspect of tri-color marking generally refers to the marking phase. During marking, the current thread can yield control to the mutator at almost any time.
Consider the scenario in the diagram: control is yielded to the mutator. The mutator makes a black object point to a white object. Then, control returns to the collector. What happens? Since black objects are considered fully processed, they won't be scanned again. Consequently, the white object now pointed to only by the black object will be mistakenly collected as garbage.
Write Barriers and Tri-color Consistency
Tri-color consistency is a property that, if maintained, guarantees that no live object is mistakenly collected. There are two main forms:
- Strong Tri-color Consistency: No black object points to a white object.
- Weak Tri-color Consistency: A black object can point to a white object, but only if there is also a grey object pointing to that same white object along some path from the roots.
Grey objects are on the worklist and will be scanned, ensuring the white object they point to is eventually reached and not lost.
Barrier techniques are used to maintain tri-color consistency. Besides classifying barriers by read/write, they can also be categorized based on the initial color (state) of the mutator.
In tri-color marking, when discussing object colors: White objects are unscanned, Grey objects are scanned but their fields aren't, and Black objects are fully scanned (including fields).
If we consider the mutator roots (stack, globals) collectively as an "object," we can classify the mutator itself as White, Grey, or Black. This concept is key to the theory of concurrent GC.
Grey Mutator Barriers
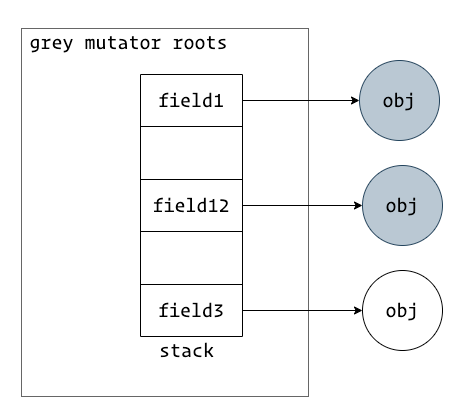
The diagram shows a grey mutator where a field points to a white object. In this state, the mutator roots must be rescanned after the initial marking phase to ensure the white object isn't mistakenly collected.
When the mutator is grey, it means there's a root field pointing to a white object. Thus, performance-impacting read barriers aren't strictly necessary to maintain consistency. Instead, write barriers are used to prevent black objects from pointing to white objects, thereby satisfying strong tri-color consistency.
var b = a.fooIf a read barrier were inserted:var b = read_barrier(a, foo)
Barrier techniques proposed by Steele, Boehm, and Dijkstra fall under the grey mutator category. Consider Dijkstra's write barrier (pseudo-code):
atomic write_barrier(obj, field, newobj):
// Perform the write first or last depending on the specific barrier
obj->field = newobj
// Ensure strong consistency: prevent black -> white pointers
if is_black(obj)
shade(newobj) // Mark newobj grey if obj is blackThe logic is simple: if the object obj being modified is black, then the newly pointed-to object newobj must be marked grey. This maintains strong tri-color consistency.
However, a consequence is that without read barriers, in an operation like var b = a.foo, if a.foo points to a white object, it's not immediately handled. Therefore, after the initial marking phase completes, a STW pause is required to rescan the mutator roots.
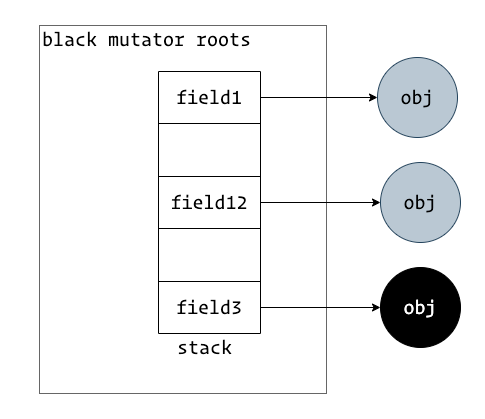
Black Mutator Barriers
The diagram shows a black mutator; all its fields have been processed, and the collector does not need to rescan the roots.
A black mutator ensures all its root fields point to either black or grey objects. The mutator itself inherently adheres to tri-color consistency. Therefore, no STW rescan is needed after marking, but a STW pause is required at the beginning of the GC cycle to scan the mutator roots and turn the mutator black.
Let's focus on Yuasa's deletion write barrier technique, based on a snapshot-at-the-beginning approach, which is a type of black mutator barrier.
Once the mutator roots are scanned (turning the mutator black), the write barrier is enabled on all threads. The pseudo-code is:
atomic write_barrier(obj, field, newobj):
// Snapshot the object being overwritten
oldobj = obj->field
// If the object being overwritten (oldobj) is white,
// mark it grey *before* performing the update.
// Grey means mark and add to worklist for the collector.
if is_white(oldobj)
shade(oldobj)
// Perform the actual write
obj->field = newobjDuring the obj->field = newobj assignment, if obj is black, this might create a black object pointing to a white newobj. The Yuasa barrier doesn't directly address this. Instead, it acts only when the pointer obj->field (pointing to oldobj) is about to be overwritten. If the oldobj being overwritten is white, the barrier marks oldobj grey, ensuring the collector eventually processes it.
In Yuasa's snapshot algorithm,
oldobj = obj->fieldrepresents the snapshot.
Yuasa's algorithm requires no read barrier and no stack rescan, and it permits the mutator to point to white objects. However, it still maintains weak tri-color consistency.
This is because during the mark phase, if newobj is referenced by a mutator root, it must have been reachable by some other path before the current write. A newobj cannot appear out of thin air and become referenced by a root during the mark phase unless it was already reachable before GC started.
var a = allocate() // A brand new object; allocation after GC starts marks it, so no issue.
var b = a.fooEven if the object pointed to by a.foo is white, it's safe because the object a itself must be grey or black.
Hybrid Write Barrier
Go version 1.8 implemented a hybrid write barrier based on Dijkstra + Yuasa, and Nature adopts a similar approach. This allows for concurrent GC with very short STW pauses.
The hybrid barrier inherits the best properties of both: it allows concurrent scanning of roots starting from the mark phase and ensures roots are black by the end of marking.
// Version 1
atomic write_barrier(obj, field, newobj):
// Yuasa part: Shade the object being overwritten if it's white
if is_white(obj->field)
shade(obj->field) // grey
// Dijkstra part (active only while stack scanning is incomplete):
// If the current goroutine/thread's stack is still grey (not fully scanned)
if stack is grey:
shade(newobj) // grey
// Actual write
obj->field = newobj
// Version 2 (conceptually identical)
atomic write_barrier(slot, ptr):
// Shade the value being overwritten (*slot) - Yuasa
shade(*slot)
// If the current stack is grey (scan incomplete) - Dijkstra
if current stack is grey:
// Shade the new value (ptr) being written
shade(ptr)
// Perform the actual write
*slot = ptrBefore the GC mark phase begins, a brief STW is needed to enable the write barrier globally. Once enabled, root scanning can proceed concurrently across multiple threads. According to the code above, if a goroutine/thread hasn't been suspended and scanned yet (its stack is "grey"), any pointer write operations within that goroutine will cause the new object being pointed to (newobj or ptr) to be marked grey (Dijkstra part). Once the current goroutine is suspended and its stack scanned (stack becomes "black"), the write barrier effectively degrades to just the deletion barrier (Yuasa part). Crucially, once the write barrier is enabled, all newly allocated objects are marked black directly.
This ensures weak tri-color consistency even when goroutines of different "colors" (scan states) operate on the same object.
STW Phases
Different barrier techniques require STW pauses at different stages:
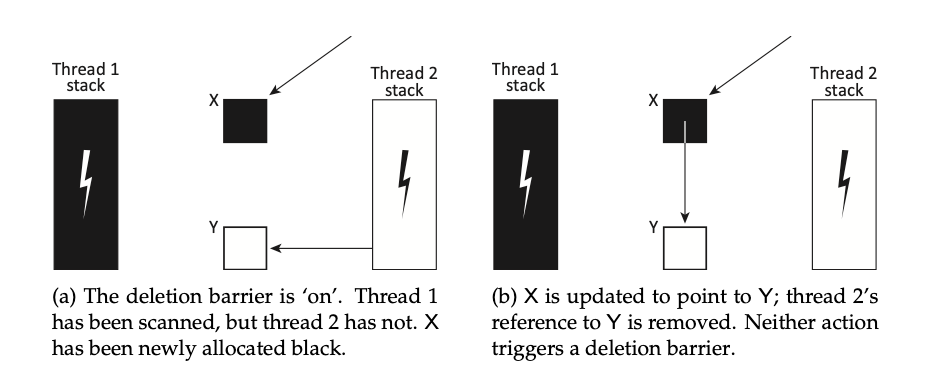
-
Grey Mutator: Requires an STW before marking starts to enable write barriers on all threads simultaneously. Otherwise, unsynchronized threads could violate consistency (e.g., create a black->white pointer undetected). It also requires another STW before marking ends to rescan the roots.
-
Black Mutator: Requires an STW before marking starts to scan roots and enable write barriers. No STW rescan is needed at the end.
-
Hybrid Write Barrier: Only requires a brief STW before marking starts to enable the write barrier. Subsequent marking and root scanning happen concurrently.
Although Nature uses a hybrid write barrier, it still requires two STW phases, but these pauses are designed to be very short.
Runtime Allocator
runtime/allocator.c#rti_gc_malloc
The allocator component is responsible for requesting memory from the operating system. Nature's memory allocator is directly inspired by Go's implementation, with some simplifications. The structure is shown below:
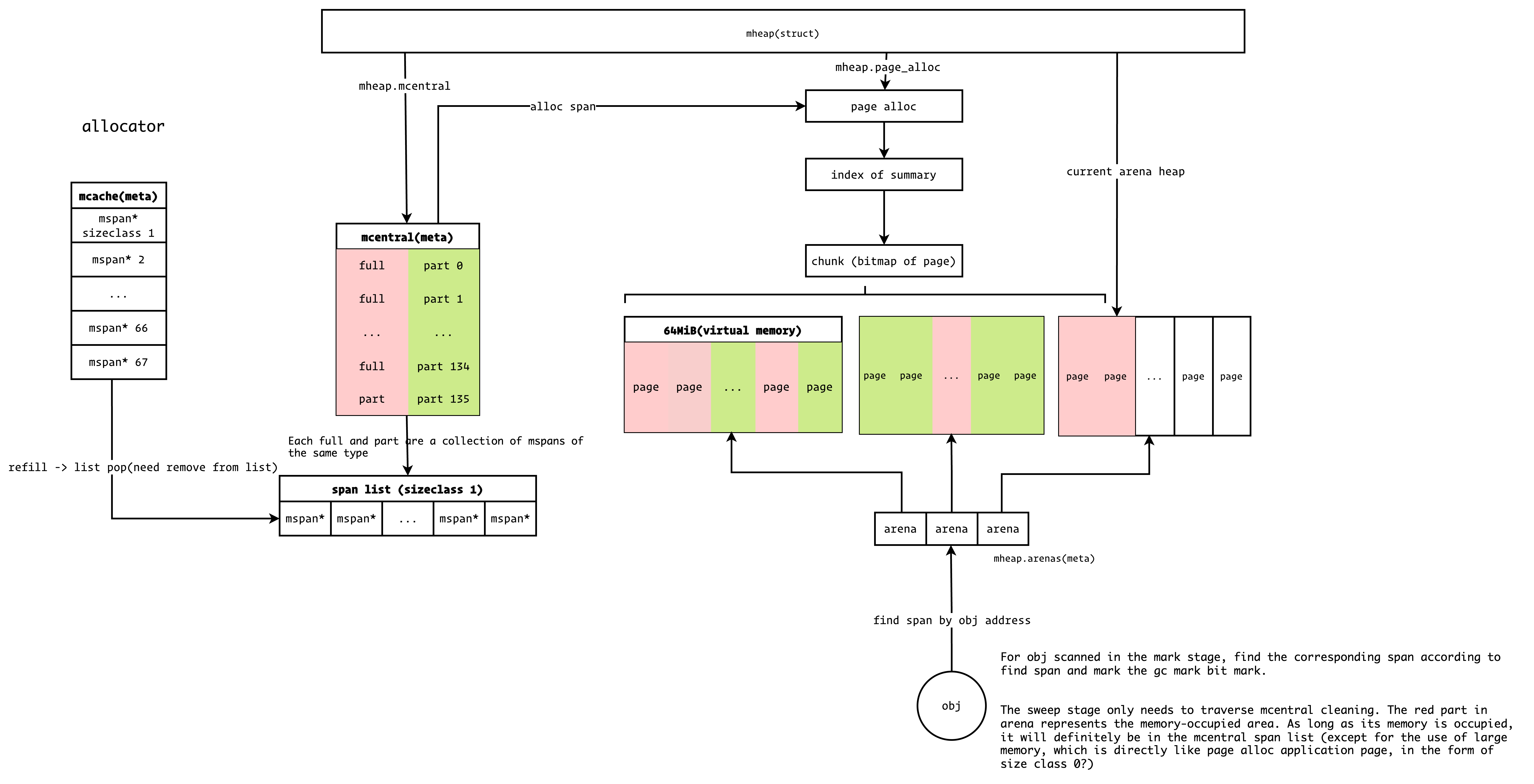
At the lowest level, Nature uses the mmap function (or equivalent) to request large chunks of memory from the OS. After the collector finishes, the madvise function (or equivalent) is used to return unused memory back to the operating system.
Runtime Libuv
libuv is a cross-platform asynchronous I/O library. Nature uses libuv to handle network I/O.
In the runtime implementation, an event loop is created for each shared processor (typically matching the CPU count) to handle asynchronous I/O events. However, libuv is not thread-safe. This conflicts with the coroutine model where coroutines can migrate between processors (threads). Therefore, care must be taken when using libuv: avoid using a libuv event loop across different shared processors.
Consider an HTTP server example (details in runtime/nutils/http.c):
- I/O events (like TCP connections, data reads/writes) are monitored and triggered by a main libuv loop (likely associated with a dedicated I/O thread or the initial thread).
- When an I/O event is ready, a new coroutine is created to handle the business logic.
- After the business logic is processed, any resulting I/O operations must be performed by sending the relevant data back to the original libuv loop (using mechanisms like
uv_async) for execution, rather than attempting the I/O operation directly within the event loop of the current coroutine's potentially different shared processor.
Runtime Reflect
utils/custom_links.h
The runtime relies on data generated at compile-time to implement features like error tracing, type reflection, and GC stack scanning. utils/custom_links.h and utils/type.h define the data structures shared with the runtime.
symdef_t: Defines the structure for symbols, including base address, size, GC marking information, etc.fndef_t: Defines the structure for functions, including base address, size, runtime information, stack layout info, etc.caller_t: Defines the structure for call sites, recording file, line, and column number information.rtype_t: Defined inutils/type.h, defines reflection information for types, including size, hash, GC bitmap (gc_bits), kind, etc.
During compilation, this data is collected and then serialized into the object file. Symbols binding this data are registered in the ELF/Mach-O symbol table.
src/build/build.c#elf_custom_links
src/build/build.c#mach_custom_links
Subsequently, the runtime only needs to declare these symbols as extern to read the relevant data.